「Power Automate Desktop」でGoogle検索の結果(タイトルとURL)を取得する方法を解説します。
以前にWebスクレイピングして、「ヤフーの虫眼鏡キーワードを取得する方法」の記事を紹介しました。
基本的にはこの流れでできるのですが、Googleの検索結果はレイアウトの階層が深くて、マウスの操作でURLを選択することが難しいです。
そこで、Googleの検索結果のURLを取得する際には、CSSセレクターを活用するといった、ちょっとしたコツが必要になります。
今回はこの部分にフォーカスして解説していきたいと思います。
Google検索の実行
Googleで検索するところまでの設定は、前述の「ヤフーの虫眼鏡キーワードを取得する方法」と同様なので省略して説明します。
簡単に説明すると、以下のアクションを追加していきます。
入力ダイアログを表示
任意の内容で良いのですが、入力ダイアログのタイトルと入力ダイアログメッセージにそれぞれ「キーワード入力」、「検索するキーワードを入力してください」としておきます。
新しいChromeを起動する
初期URLとして「https://www.google.co.jp/」とします。
Webページ内のテキストフィールドに入力する
UI要素としてGoogleの検索窓のテキストフィールドを指定します。
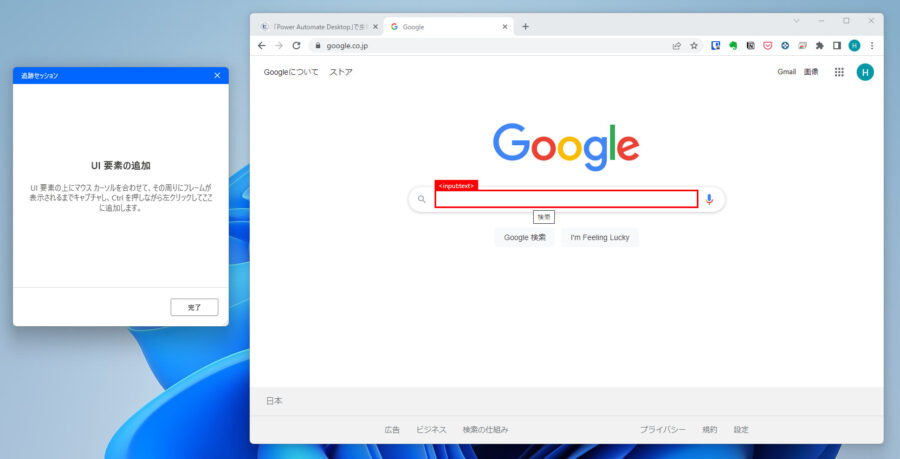
入力するテキストは「入力ダイアログを表示」で指定した「%UserInput%」になります。
キー送信
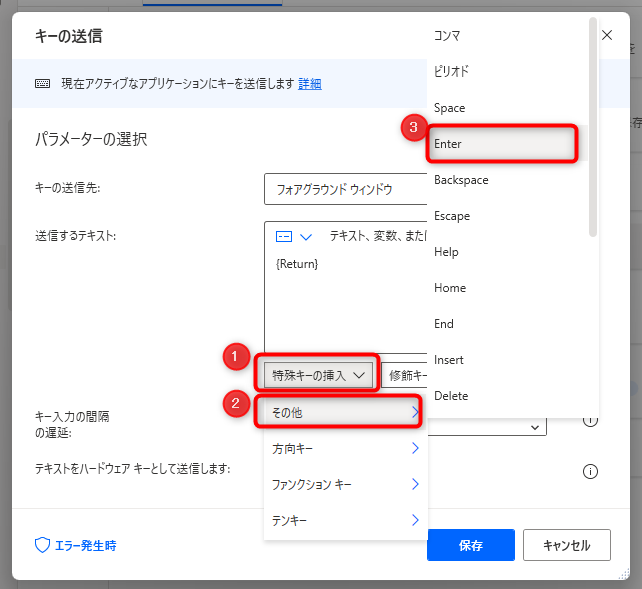
「Google検索」のクリックが動作しないので、今回はEnterキーを押下して検索を実行する方法を使います。
「キー送信」のアクションを追加したら、「特殊キーの挿入」-「その他」-「Enter」と選択して保存します。
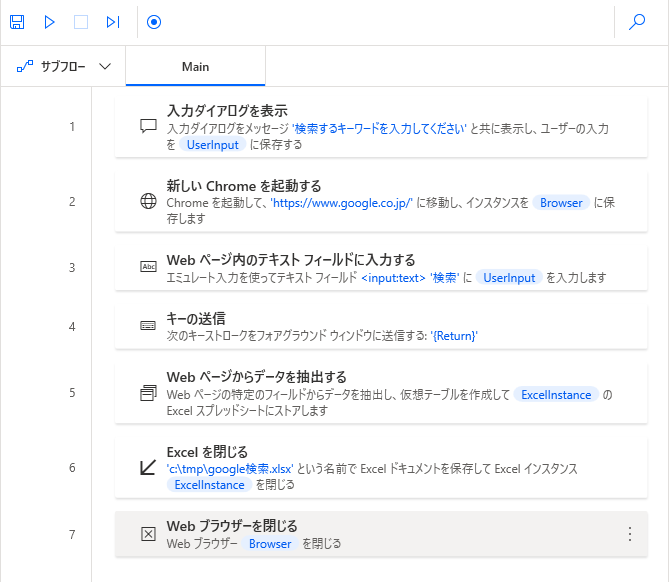
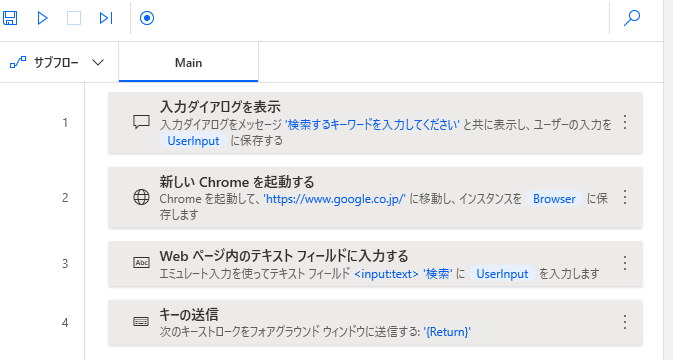
以上、Googleで検索するところまでの設定となり、ここまでのフローをまとめると以下のようになります。
検索結果のページのデータ抽出
続いて、Google検索の結果として表示されたページのタイトルとURLを取得していきます。
アクションの「Webページからデータを抽出する」をMainフローにドラッグします。

以下の「Webページからデータを抽出する」の設定画面を表示されている状態でブラウザを起動して、検索結果と同じページを表示させます。
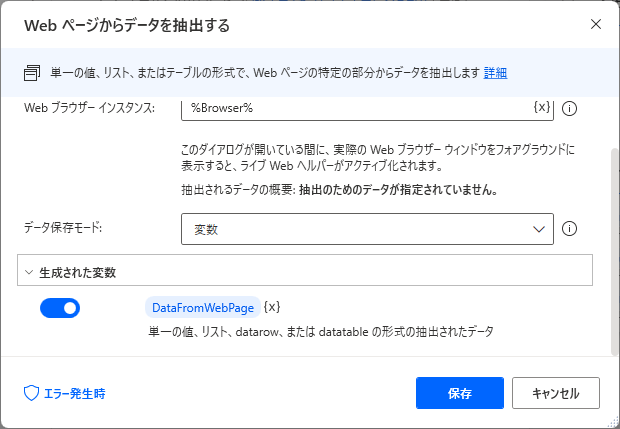
まず、タイトルを取得するため、検索結果の2番目のページを右クリックして「要素の値を抽出」-「テキスト」を順番に選択します。
ポイント
Googleの検索結果の1番目のページはフォーマットが違うことが多いので2番目を選ぶと良いです。

続けて、検索結果の3番目のページも同様に、右クリックして「要素の値を抽出」-「テキスト」を順番に選択します。
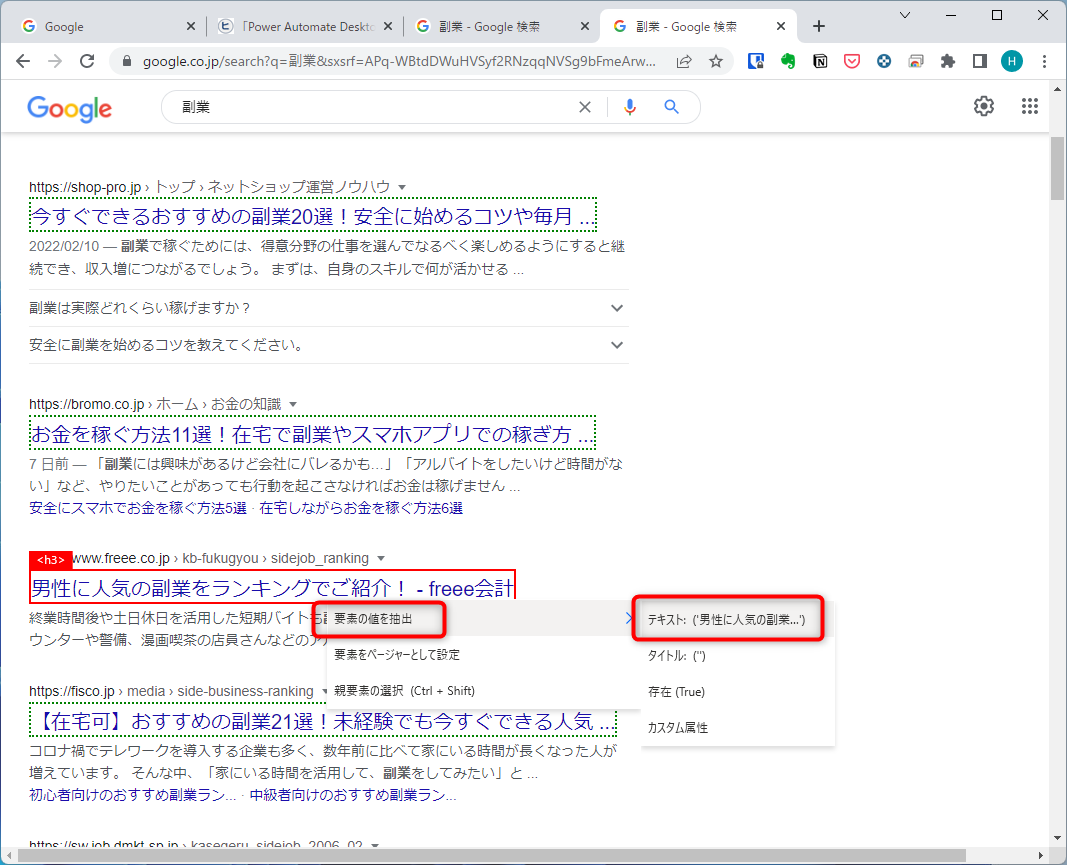
このように2つ以上選択することによって、自動的にリストとしてすべてのタイトルを(1番目の検索結果も含めて)取得できるようになります。
ライブWebヘルパー画面には次のように一覧で表示されます。

引き続き、URLの取得を行います。
同様の方法で取得できればいいのですが、Googleの検索結果のページはレイアウトの階層が深くて、マウスの操作でURLを選択することが難しいです。
URLは「Aタグ」に含まれているので、右クリックでAタグを選択したいのですが、どうしても「H3タグ」になってしまいます。
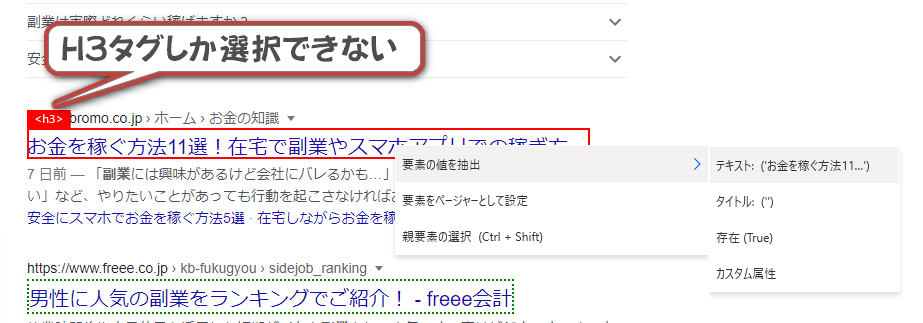
そこで、CSSセレクターという機能を使います。
手順は次の通りです。
ライブWebヘルパー画面で詳細設定をクリックします。

現状は項目が1つなので抽出が「リスト」になっていますが、タイトルとURLの2つの項目を取得するので、ここを「テーブル」に変更します。
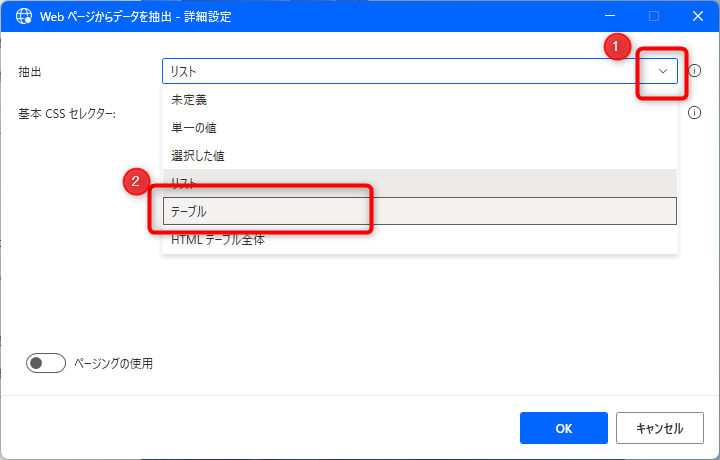
CSSセレクターの2つ目の入力フィールドが表示されるので、ここに以下の内容を設定して、OKボタンをクリックします。
CSSセレクター:div > div:eq(0) > div > a
属性:href

CSSセレクターの設定が完了すると、ライブWebヘルパー画面にはタイトルとURLの一覧が表示されるので「終了」をクリックします。

「Webページからデータを抽出する」の設定画面に戻ったら、データ保存モードとして「Excel スプレッドシート」を選択して「保存」をクリックします。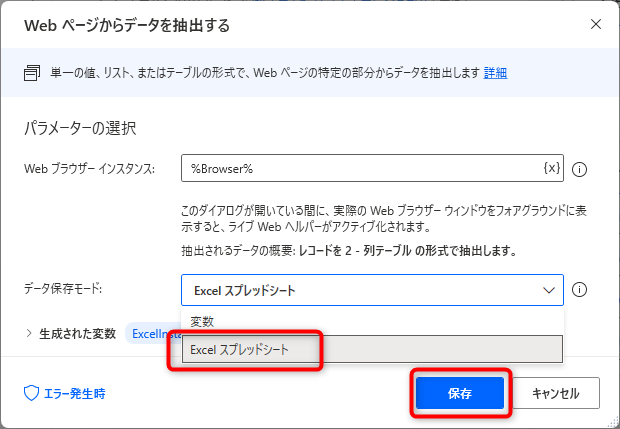
これで、検索結果のタイトルとURLを取得する設定は終了です。
CSSセレクターについての補足
ここでCSSセレクターについて補足します。
手順では「div > div:eq(0) > div > a」としていますが、この値はどうやって判断するのでしょうか。
通常はChromeブラウザのデベロッパーツールなどを使用して調べます。
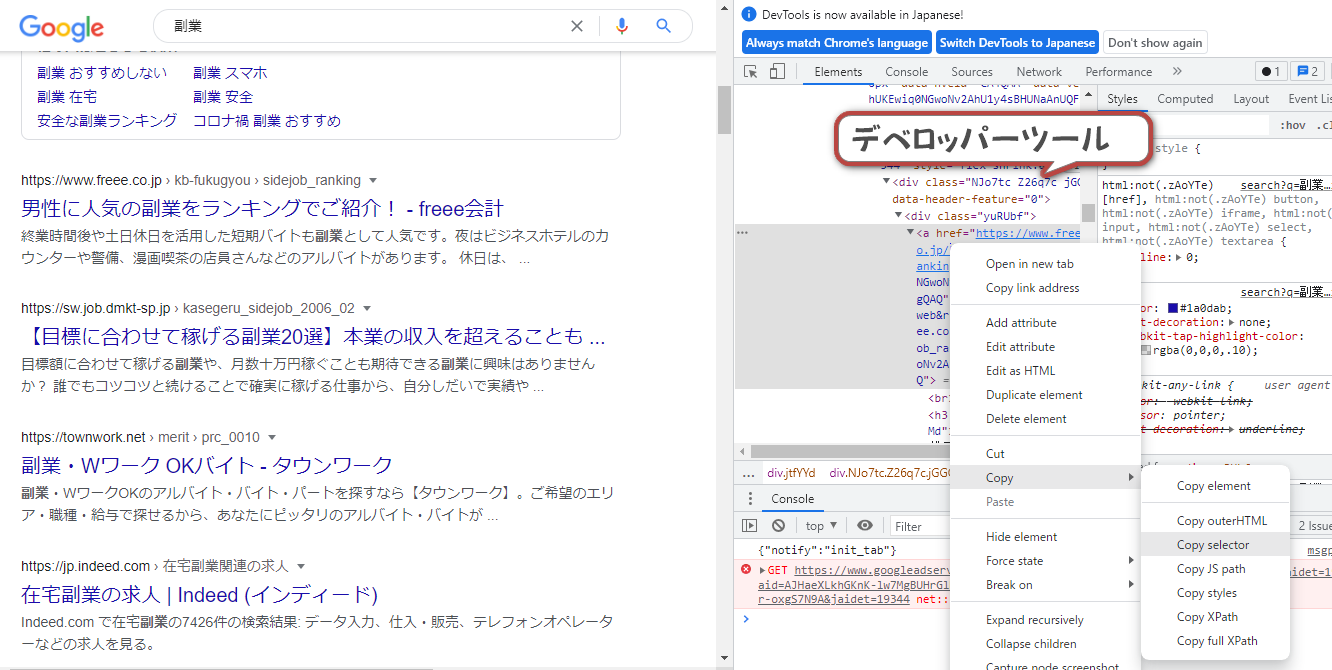
ただ、デベロッパーツールで調べる方法は、少し難易度が高いのでここでは詳しい説明は省略します。
今回は、タイトルを取得したときに設定されていたCSSセレクターの値から考えてみます。
このタイトルのCSSセレクターは「div > div:eq(0) > div > a > h3」となっていました。
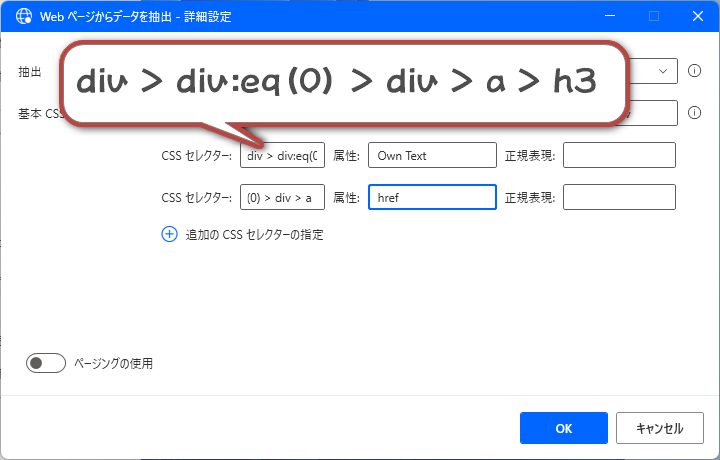
これはタイトルが含まれる「H3タグ」のテキストの値を取得することを意味します。
URLは「Aタグ」に含まれるので、ここから「> h3」を省いて「div > div:eq(0) > div > a 」とすることで「Aタグ」の内容が取得できるか等、試してみると良いです。
とりあえず、Google検索の検索結果からURLを取得する場合は、CSSセレクターは「div > div:eq(0) > div > a 」で大丈夫だったのでこれを利用してください。
保存と終了
最後にエクセルに保存するアクションを追加します。
アクションの「Excelを閉じる」をMainフローにドラッグします。

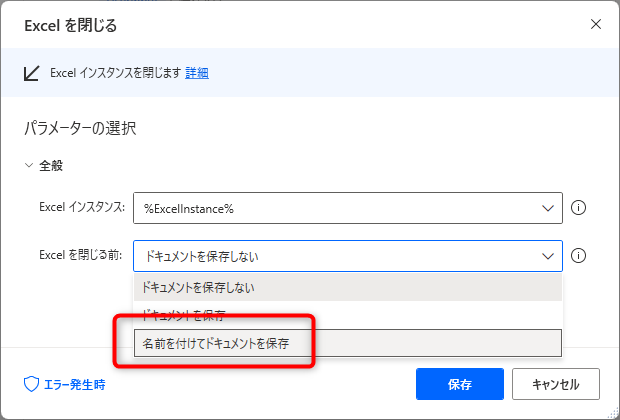
Excelを閉じる前の処理として、「名前を付けてドキュメントを保存」を選択します。
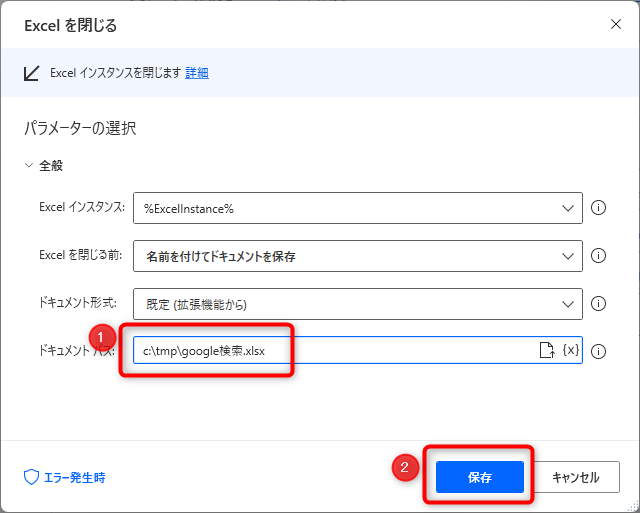
ドキュメントパスを入力するためのフィールドが表示されるので、そこにExcelファイルを保存したいパスを入力して、「保存」をクリックします。
以上、処理は終了ですが、アクションの「Webブラウザーを閉じる」をMainフローにドラッグしておきましょう。
実行
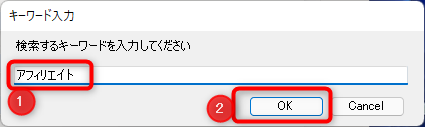
実行すると、キーワードを入力するためのメッセージボックスが表示されるので、ここに検索したいキーワードを入力して「OK」をクリックします。
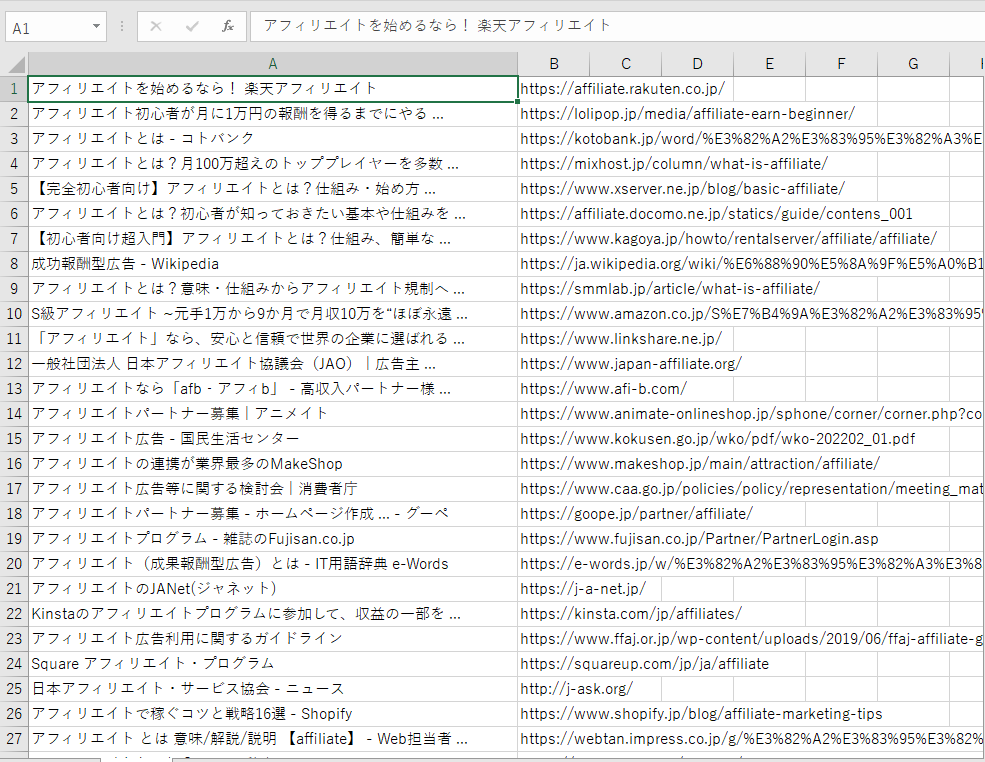
キーワードでGoogle検索した検索結果のページタイトルとURLが保存された以下のようなExcelファイルが自動で生成されます。
今回の全体像としては次の通りです。